September 12, 2006
| Document Information | |
|---|---|
| Organisation | Hogeschool voor de Kunsten Utrecht (HKU) |
| Version | 0.3 |
| Status | proposal |
Abstract:
This document provides an introduction into the principles of archiving and version control of software and documentation.
Another purpose of an archiving system is version control. This is the process of giving version numbers or names to specific releases of your product. With a well maintained archiving system it is possible to retrieve all files belonging to any release that was made, e.g. for maintenance purposes.
In general, a version control system can be seen as a large pool of files, called a repository, with a management system that takes care of the file handling.
However, it is much more than just a file system, it stores the files in such a way that it becomes possible to retrieve any previous version that was ever stored. It does this in an efficient way, much more efficient than just storing all versions of all files, but e.g. by only storing differences between two adjacent versions. On top of that, the version control system makes it possible to compare any two versions of a file, including your own working copy, to see what the differences are or to track how a file developed over time.
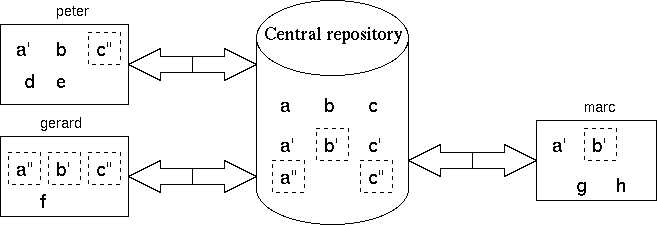
To illustrate the use of a central repository, the following picture shows the working directories of three people working on the same project.
In the repository are 3 files: a, b and c, of which a number of versions are stored. Newer versions get more quotes to indicate that these are different instances of the same file.
In each working directory we see some files that are also stored in the central repository of the archiving system. Beside that, we also see files in working directories that are not in the repository and files in the repository that don't show up in either one of the working directories. The files with a square drawn around it are (based on) the most recent versions of a specific file in the archive. A more detailed discussion follows.
Let's start with Peter's files. He's got three files that are also in the repository: a', b and c". The files a' and b are (based on) older versions of files a and b. This means that files a and b were updated in the archive after Peter got them from the archive or submitted them himself. The file c" is equal to the most recent version of file c that is stored in the archive. There are also two files d and e in his working directory that are not in the archive at all. No problem, this might be temporary files, files that he wishes to add to the archive at later moment or Peter's own utilities.
Gerard has three files that are all in sync with the archive. He's probably just done an update on his working directory. There's also a file f which is not (yet) in the archive.
Marc is working with old stuff. Files a and b are based upon really old versions and file c isn't even in his working directory yet. Looks like its getting time for an update. Or maybe he's working on a version of the software that doesn't need file c, but still it's time for updating files a and b then. The files g and h are not (yet) in the archive.
Any of the three developers can get files from the archive, make changes and update the file in the archive. Thus it can happen that you get file a from the archive while it has version a' and shortly after that someone else updates file a, which then becomes version a" and at the same moment your file is no longer in sync with file a in the archive. For the same reason you must always bring your files up to date just before checking them in to the archive. This means that all changes in the archive are first merged into your working copy, an action that a good archiving system does automatically for you. After this merge you have a working copy that is based on the most recent version in the archive and on top of that contains your changes. This merging process is mostly harmless but there are situations that cause conflicts. Read more about merging in the chapter about conventions.
Each version of a file has a unique revision number. Revision numbers look like `1.1' or `1.2' and are given to your files automatically by the revision control system when you check in your files.
A release is a collection of software, tools, hardware and documents that belong together at a certain moment in time. A release is made by putting a label on every file in the archive that should be in the release. At a later time it is then possible to retrieve the entire release collection from the archive by specifying the release label.
File headers provide information about the file, such as the name of the author, the purpose of the file, description of modifications, modification dates etc.
Especially for program code some of this information is very useful, therefore all program code files should have a file header conforming to a format that is more or less exactly generic, except for differences due to the way comments are handled in the various programming languages.
The following applies to CVS as a revision control system. For all files stored in the revision control system an ID, version number and log information are kept. Using special keywords, like e.g. $Revision: 1.7 $ this information can be made explicit in the actual files. The revision number and log information are incorporated in file headers for all program files. The revision number may also be very useful in documentation and can be used in e.g. XML or HTML files that are under version control.
An example of a file header for C or C++ files is shown here:/******************************************************************** * (c) Copyright 2002, Hogeschool voor de Kunsten Utrecht * Hilversum, the Netherlands ********************************************************************* * * File name : archiving.xml * System name : mediate * * Version : $Revision: 1.7 $ * * * Description : A data preservation fairytale * * * Author : Marc Groenewegen * E-mail : marcg@dinkum.nl * * ********************************************************************/ /************ $Log: archiving.xml,v $ Revision 1.7 2007/10/09 14:16:57 marcg subversion instead of cvs Revision 1.6 2005/09/14 20:30:43 marcg from draft to proposal Revision 1.5 2003/05/05 15:21:49 marcg Set current date Revision 1.4 2002/04/24 15:56:23 marcg Changed titlepage layout according to new format Added LaTeX control commands for paragraphs and some minor improvements Revision 1.3 2002/03/27 21:24:48 marcg Lots of additions Revision 1.2 2002/03/26 10:29:28 marcg Numerous additions *************/
Examples of binary files
Examples of text files
Executables derived from source files in the archive are only stored in the archive when they belong to a release. The reason for this is that executables normally can be generated from a set of source files and because these source files are already available in the archive it is not necessary to store the executables.
This reasoning can be extended to all files that can be generated from files already in the archive.
An exception to this rule is made for executables being part of a release. In theory it is possible to reconstruct entire releases from previous versions of source files but in practice this is not always the case. For that reason, for every major release, all generated files are also packed in a release file and stored in the archive for future use in e.g. debugging.
What causes merge conflicts ? The most obvious example of a merge conflict is when you and one of your colleagues are working on the same file. You both have your own working copies so you're free to modify what you want, as long as you merge the latest version in the version control system and your own file just before check-in. Now suppose you remove a specific section and put the file back into the version control system. Your colleague then wants to put his working copy into the system and updates his file before you commit your version to CVS. His version will then still contain the section you just removed.
Making sure you don't put rubbish into the archive is easy. When you've finished editing your working copies, update all files that are needed to build the program so they are in-sync with the archive. Rebuild your program from your working files. If the build process is successful and your program doesn't blow up in your face when you start it, you're ready to submit your changed working copies into the archive.
If the version control system offers both reserved and unreserved checkout, unreserved checkout is preferred. Reserved checkout means that the file gets locked upon checkout, thus preventing other users to work on the same file. The lock is freed after check-in. In most cases, this mechanism is unnecessary and causes more trouble than it prevents. The most prominent disadvantage is that users tend to forget unlocking files, thus slowing down the development.
One case for which reserved checkouts are useful concerns binary files. If there is no merge tool for binary data, which is often the case, then conflicts due to file updates by multiple users are often hard to solve. In my opinion however, reserved checkouts are mainly a replacement for bad group communication so I propose not to use them unless you hate your colleagues and are looking for a way to really annoy them.
| CVS | http://ximbiot.com/cvs |
| CVS documentation | http://ximbiot.com/cvs/manual |
| Tcl/Tk | tcl.sourceforge.net |
| TkCVS for UNIX/Linux and Windows | twobarleycorns.net |
| MacCVS Pro | www.maccvs.org |