September 7 2004
| Document Information | |
|---|---|
| Organisation | Hogeschool voor de Kunsten Utrecht (HKU) |
| Version | 0.2 |
| Status | proposal |
Abstract:
This document provides an introduction into the use of the CVS version control system.
CVS stands for Concurrent Versions System. CVS is a source control system. It allows you to store and retrieve multiple versions or revisions of the same file or files. This makes it possible to trace back to the history of files, see the way they developed, who worked on them and see the reasoning behind important implementation decisions.
CVS helps in efficient use of disk space needed for the archive. You could of course save every version of every file you have ever created and waste an enormous amount of disk space. Instead, CVS stores all the versions of a file in a single file in a clever way that only stores the differences between versions.
CVS also helps you if you are part of a group of people working on the same project. It is all too easy to overwrite each other's changes unless you are extremely careful. With CVS several people can work on the same files simultaneously without damaging each other's work.
An important feature of CVS is the ability to tag labels to collections of files. This is common practice for grouping together all files that are needed to construct a software release. CVS is able to extract the entire collection of files labeled for such a release at any time.
This document offers a quick start with CVS and a hands-on example. More information about the ideas behind archiving and version control can be found in the document "Archiving and version control".| CVS home page | cvshome.org |
| CVS documentation | cvshome.org |
| Tcl/Tk | tcl.sourceforge.net |
| TkCVS | twobarleycorns.net/tkcvs.html |
| WinCVS for Windows and MacCvsX for OS-X | www.wincvs.org |
| MacCVS Pro (seems to be a bit buggy) | www.maccvs.org |
Information about tkCVS can be found on the tkCVS site but I didn't find a useful manual there. The help menu on the tool itself is quite good though.
In general, CVS consists of a client and a server program. It is possible to use CVS on the same machine that hosts the CVS repository, but a more common situation is that in which the developers all use CVS on their machines somewhere on the local network, or even the internet, and all use the same central archive which is located on a CVS server.
After downloading and installing a CVS client for your computer, the program has to be configured. The one and only thing that is required to tell your client is where to find its server, or more specifically, where it can find its repository. Other configuration is client-specific and mainly addresses preferences for displaying information or check-in and check-out behaviour.
cvs -d /usr/local/cvsroot update mediatein which /usr/local/cvsroot is the name of the repository on the local machine. The disadvantage of this invocation is that you have to specify the repository in every CVS command.
A more commonly used way of telling CVS where to find your repository is to create an environment variable CVSROOT.
On UNIX systems the way to specify environment variables depends on the type of shell you use. In general we have two flavours:
csh or tcsh users put the following line in their `.cshrc' or `.tcshrc' files:
setenv CVSROOT /usr/local/cvsroot
sh and bash users put these lines in their `.profile' or `.bashrc':
CVSROOT=/usr/local/cvsroot export CVSROOT
On Windows systems, the CVSROOT variable is specified in the environment menu.
In the MacCVS client, CVSROOT is specified in the program itself.
setenv CVSROOT :pserver:myname@cvs.hku.nl:/usr/local/cvsroot
In this example, the pserver protocol is used to communicate to the CVS server on cvs.hku.nl. The repository on cvs.hku.nl resides in the directory /usr/local/cvsroot. The user 'myname' must have an account on the server and to use the repository, the user must have read and/or write permissions on (parts of) the repository.For those who wish to use CVS on the command line, e.g. in a telnet window on a remote machine, the following is a list of frequently used commands:
*** setting up a repository
cvs init
*** creating a new project in the repository
cvs import -m "name" project tag start
This is done in the original directory. The parameter 'name' specifies
the name of the project in CVS and is generally the same as the project
directory. The parameter 'tag' is a Vendor tag, just make something up.
The parameter 'start' is a release tag, make something up for that one
as well.
*** checking out an entire project
cvs get project
*** checking out file(s) from subdir/ under project
cvs get <project/subdir/file(s)>
*** setting tags to an entire directory
cvs tag <tagname> . from toplevel project dir
*** show all status information, the '-v' makes sure you also get to
see the tags
cvs status -v <file(s)>
*** show log information
cvs log [file(s)]
*** update the file(s) w.r.t. the file in the repository, optionally
specifying from which release
cvs update [-r revision] <file(s)>
*** reset sticky tags
cvs update -A <file>
*** show differences between your working copy of the specified file and
its counterpart in CVS, optionally specifying its revision number.
If no file specified, CVS will report the differences to all files
under the current directory that are under CVS control
cvs diff [-r revision] [file(s)]
*** show differences while ignoring differences in white space
cvs diff -w
There are several web-clients for CVS but I haven't found any that can do check-ins so I didn't do further research on those. There is however a graphical tool called tkCVS that is written in tcl/tk and is in fact a shell upon CVS. It is available for UNIX and Windows. For Windows and OS-X, there is WinCVS.
Some advantages of a graphical tool compared to the command-line interface:
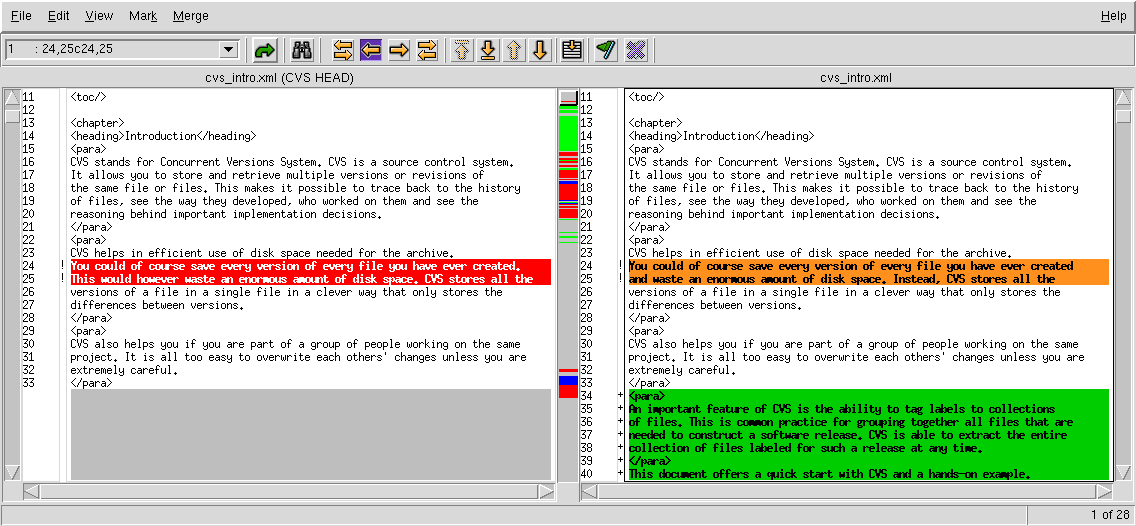
The following picture shows the two-window compare option of tkCVS:
Examples of binary files
Examples of text files
/******************************************************************** * (c) Copyright 2002, Hogeschool voor de Kunsten Utrecht * Hilversum, the Netherlands ********************************************************************* * * File name : * System name : * * Version : $Revision: 1.8 $ * * * Description : * * * Author : * E-mail : * * ********************************************************************/ /************ $Log: cvs_intro.xml,v $ Revision 1.8 2005/10/12 18:06:58 marcg link update Revision 1.7 2005/09/14 20:30:43 marcg from draft to proposal Revision 1.6 2003/05/05 15:21:49 marcg Set current date Revision 1.5 2002/06/14 23:22:59 marcg Small changes Revision 1.4 2002/04/24 19:25:51 marcg Minor changes Revision 1.3 2002/04/24 17:37:15 marcg Changed titlepage layout according to new format Added LaTeX control commands for paragraphs Major update of the hands-on example Revision 1.2 2002/03/27 21:25:00 marcg Lots of additions Revision 1.1.1.1 2002/03/12 10:39:05 marcg HKU documenting course *************/To put the ID-marker in the compiled object files as well, put it into a literal character string. In C, this is done by adding following line:
static const char RCSID[] = "$Id: cvs_intro.xml,v 1.8 2005/10/12 18:06:58 marcg Exp $"; NB: This only applies to the source files, not the header files, because this statement will allocate storage.
The following is a checklist for checking-in files into CVS:
Some guidelines to follow when making a new release:
In CVS, groups of files are arranged into modules for easy access. Module Browser window.
- Working with files from the repository Using the Module Browser window, you can select a module to check out. Each module has a module code which is displayed as you browse through the module tree. When you check out a module, a new directory is created in your working directory with the same name as the module code.
You can use the simple file management and editing features of TkCVS to work with files in this directory, or you may use your own text editor, word processor, or whatever to work with the files.
Once you have finished your edits (or whenever you have reached a stable stage in your development, or possibly even on a daily basis), you can check files back in to TkCVS
- Tagging and Branching You can tag particular versions of a module or file in the repository. Normally you will do this when your programs are ready to be released into a testing or production environment. Tagging is useful for taking snapshots of what the repository contained at a particular date (for example you can tag all of the files associated with a particular software release).
- Exporting ! Shipping a release without the CVS directories. Through module browser ! Tip: after changing working directory press ENTER otherwise it doesn't stick
-Importing: how do we import a module as part of a bigger group of modules ? E.g. mediate-signature-database ---- module path
Once a software release has been tagged, you can use a special type of check out called an export. This allows you to more cleanly check out files from the repository, without all of the administrivia that CVS requires you to have while working on the files. This type of facility is useful for delivery of a software release to a customer.
Other features of TkCVS allow you to tag files, add new files or delete files from the repository, or view and print reports about the repository contents. You can also search the module database for module codes, module names, and keywords within a module name.
Add file, then commit (check in)
Remove... is this permanent ?
Update button
Directory tag name zie je alleen bij uitgecheckte dir van bep. revision
Customising tkcvs
tkdiff program - start it and look into its Help ---- possible diff while skipping white space ? --- yep, select 'diff -b' in edit-preferences menu, better not make this setting permanent
tkdiff right button in window
Keyboard navigation: f First diff c Center current diff l Last diff n Next diff p Previous diff 1 Merge Choice 1 2 Merge Choice 2
Merging ---- eerst merge mode kiezen, dan via Merge menu mergen
To merge the two files, go through the difference regions (via "Next", "Prev" or whatever other means you prefer) and select "Left" or "Right" (next to the "Merge Choice:" label) for each. Selecting "Left" means that the the left-most file's version of the difference will be used in creating the final result; choosing "Right" means that the right-most file's difference will be used. Each choice is recorded, and can be changed arbitrarily many times. To commit the final, merged result to disk, choose "Write Merge File..." from the Merge menu.
Merge Preview
To see a preview of the file that would be written by "Write Merge File...", select "Show Merge Window" in the View menu. A separate window is shown containing the preview. It is updated as you change merge choices. It is synchronized with the other text widgets if "Synchronize Scrollbars" is on. merging !!! cvs update
In general, most merge conflicts are caused by overlapping changes that can not be uniquely identified by CVS.
The following example is taken from the CVS manual.
Suppose revision 1.4 of `driver.c' contains this:
#include <stdio.h>
void main()
{
parse();
if (nerr == 0)
gencode();
else
fprintf(stderr, "No code generated.\n");
exit(nerr == 0 ? 0 : 1);
}
Revision 1.6 of `driver.c' contains this:
#include <stdio.h>
int main(int argc,char **argv)
{
parse();
if (argc != 1)
{
fprintf(stderr, "tc: No args expected.\n");
exit(1);
}
if (nerr == 0)
gencode();
else
fprintf(stderr, "No code generated.\n");
exit(!!nerr);
}
Your working copy of `driver.c', based on revision 1.4, contains this before
you run `cvs update':
#include <stdlib.h>
#include <stdio.h>
void main()
{
init_scanner();
parse();
if (nerr == 0)
gencode();
else
fprintf(stderr, "No code generated.\n");
exit(nerr == 0 ? EXIT_SUCCESS : EXIT_FAILURE);
}
You run `cvs update':
$ cvs update driver.c
RCS file: /usr/local/cvsroot/yoyodyne/tc/driver.c,v
retrieving revision 1.4
retrieving revision 1.6
Merging differences between 1.4 and 1.6 into driver.c
rcsmerge warning: overlaps during merge
cvs update: conflicts found in driver.c
C driver.c
CVS tells you that there were some conflicts. Your original working file is
saved unmodified in `.#driver.c.1.4'. The new version of
`driver.c' contains this:
#include <stdlib.h>
#include <stdio.h>
int main(int argc,
char **argv)
{
init_scanner();
parse();
if (argc != 1)
{
fprintf(stderr, "tc: No args expected.\n");
exit(1);
}
if (nerr == 0)
gencode();
else
fprintf(stderr, "No code generated.\n");
<<<<<<< driver.c
exit(nerr == 0 ? EXIT_SUCCESS : EXIT_FAILURE);
=======
exit(!!nerr);
>>>>>>> 1.6
}
Note how all non-overlapping modifications are incorporated in your working
copy, and that the overlapping section is clearly marked with
`<<<<<<<', `=======' and `>>>>>>>'.
You resolve the conflict by editing the file, removing the markers and the
erroneous line. Suppose you end up with this file:
#include <stdlib.h>
#include <stdio.h>
int main(int argc,
char **argv)
{
init_scanner();
parse();
if (argc != 1)
{
fprintf(stderr, "tc: No args expected.\n");
exit(1);
}
if (nerr == 0)
gencode();
else
fprintf(stderr, "No code generated.\n");
exit(nerr == 0 ? EXIT_SUCCESS : EXIT_FAILURE);
}
You can now go ahead and commit this as revision 1.7.
$ cvs commit -m "Initialize scanner. Use symbolic exit values." driver.c
Checking in driver.c;
/usr/local/cvsroot/yoyodyne/tc/driver.c,v <-- driver.c
new revision: 1.7; previous revision: 1.6
done
For your protection, CVS will refuse to check in a file if a conflict occurred
and you have not resolved the conflict. Currently to resolve a conflict, you
must change the timestamp on the file, and must also insure that the file
contains no conflict markers. If your file legitimately contains conflict
markers (that is, occurrences of `>>>>>>> ' at the start
of a line that don't mark a conflict), then CVS has trouble handling this and
you need to start hacking on the CVS/Entries file or other such workarounds.
The following subjects will be addressed in this example:
We start with a top-level directory 'bicycle' containing subdirectories src (for source files), include (for header files) and doc (for documentation) and we fill those directories with the following files:
src
/**************
* bike_main.c *
**************/
#include <stdio.h>
#include <stdlib.h>
#include <pedal.h>
#include <wheel.h>
main()
{
int pedalturns=3;
double wheelturns;
double movement;
wheelturns=pedal(pedalturns);
movement=wheel(wheelturns);
printf("We're moving %f meters\n",movement);
}
/********** * pedal.h * **********/ extern double pedal(int); #define RATIO 0.5
/**********
* pedal.c *
**********/
#include <stdio.h>
#include <pedal.h>
double pedal(int turns)
{
return (double)turns * RATIO;
}
/********** * wheel.h * **********/ extern double wheel(double); #define PERIMETER 3.1415
/**********
* wheel.c *
**********/
#include <stdio.h>
#include <wheel.h>
double wheel(double turns)
{
return turns * PERIMETER;
}
We want to put the entire directory tree, containing subdirectories
src, include and doc, into CVS. We do this by going to
the top-level directory of our project and opening
the module browser in tkCVS. In the 'Module' line we enter the name
for our module, in this case 'bicycle'. In CVS, this will be the
top-level name for our project.
In the 'Current Directory' line, the top-level directory of our project
must be shown. If that is not the case, change it.
The 'import' button will bring the entire tree under CVS control. When using CVS on the command line, the next step will be to rename the original top-level directory and check-out the project to your local file system. This step is necessary because CVS will then put some control information into the tree. When using tkCVS, this step of renaming your tree to a temporary tree and checking out the newly entered project is done automatically.
/**************
* bike_main.c *
**************/
#include <stdio.h>
#include <stdlib.h>
#include <pedal.h>
#include <wheel.h>
main(int argc,char **argv)
{
int pedalturns;
double wheelturns;
double movement;
if(argc==2)pedalturns=atoi(argv[1]);
else{
printf("Please enter the number of pedal turns\n");
exit(0);
}
wheelturns=pedal(pedalturns);
movement=wheel(wheelturns);
printf("We're moving %f meters\n",movement);
}
Change your local copy of bike_main.c according to the given example and ask tkcvs to show the differences between your local (changed) copy and the latest revision stored in the CVS repository.
To be sure that your file is in sync with the archive, update your file before check-in. Rebuild the program and when you're satisfied with the changes, commit the file to CVS, writing some words about the change in the revision log. Afterwards, take a look at the revision log.
/****************** * bike_design.xml * ******************/ <?xml version="1.0"?> <!DOCTYPE doc SYSTEM "/usr/local/xslt/doc.dtd"> <doc style="main.css"> <?xml-stylesheet type="text/css" href="xmldoc.css"?> <report> <title author="Marc Groenewegen (marcg@dinkum.nl)"> <para>Bicycle design doc</para> </title> <toc/> <chapter> <heading>Introduction</heading> <para> This document describes the design of a bicycle tour. </para> </chapter> </report> </doc>In tkCVS we can now add the file by pressing the '+' button or selecting the 'Add' option from the File menu. Adding a file only tells CVS that the file will be placed under CVS control, but the file is NOT checked in ! Therefore, an 'add file' action is mostly followed by a check-in.