Links
- Official GIT site
- Github
- Building Krita on Linux for cats .. mentioned here because of the great illustrations!
- O'Reilly book "Version Control with Git" Recommended!

Manual pages for Git
- man Git
- man Git-add
- man Git-commit
- man Git-diff
- In general: man Git-
What to use Git for?
What kind of things would you want to do with Git?- make a new (local) repository for a new or existing single user project
- make a new (remote) repository for a new or existing multi user project
- manage local files and a local repository: add/commit/checkout
- manage files and a remote repository: push/pull/fetch
- view changes between revisions: diff
- take part in an existing project: clone/push/pull
- work on features, bugfixes and other developments outside the release track
Git clients
For most operations on your local repositories and remote ones, the git commands in your terminal are the most efficient. In some cases though, a graphic client is really useful, e.g. when inspecting changes after fetching from a shared repository or for an intuitive view of the (branching) history of a project. Some examples of clients:- git in the terminal (preferred way for most operations)
- gitg - graphic client
- gitk - graphic client
- GitHub - website with support for community-based develoment, free for open-source projects, for closed projects a fee applies
- GitLab - Github-like system with support for community-based develoment, corporate version
Repository, index and working directory
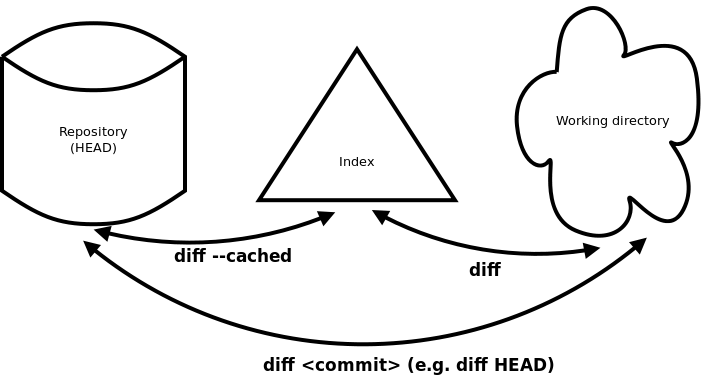
This diagram shows the organisation of your working directory with your files, the repository and the index which resides between them. The commands are explained in the text below.
Getting started with a local repository
Commmand:git init
Add some files in two steps: first add them to the index, then commit the
index to the repository:
git add <some files>
git status (shows staged, unstaged and untracked files)
git commit
Preferably don't add entire folders, as they may contain files you would
rather not put in git, such as executables, .o files, (large) media files
and other things that either can be made again from the source code or can
be obtained from other sources.
Git status shows which files have changed w.r.t. the most recent version in the repository, which files are in the index and will be commited in the next commit and 'Untracked files': i.e. files that Git knows nothing about because they are not in the repository.
Instead of 'modified', it can show 'typechange', which means that the file has changed from a proper file into a symlink or vice versa.
Now take a look what has been stored into the repository:
git status
git ls-tree HEAD
git show (--name-only)
Make some modifications
See what has been changed with respect to the HEAD of the repository:git status -sgit ls-tree HEADgit show (--name-only)
git commit doesn't do anything if we don't add some files first. If you
want you can skip the 'add to index' step by using
git commit <some files> -m "Log message"
but this is not recommended.
See our loggging and other information:
git log
git show (--name-only)
git show <a specific commit or HEAD>
git add -u (add all modified files already under Git control to the index)
git commit (commits all files in the index)
or
git commit -a (adds everything to the index and commits the index)
make modifications, then
git diff
git add <files>
git commit
git diff
Git diff with external DIFF program
Git can show the differences between two versions stored in its archive or a stored version versus your current file. The default output however is in a format that is hard to interpret for a human reader. A much more useful way is to put both versions side by side with their changes marked in different colors. For this purpose a lot of external viewers are available.
Asking Git to show the differences between your working copy and the version stored in the repository, Git will first check whether the environment-variabele GIT_EXTERNAL_DIFF exists. If so, it sends both files to an external diff program, otherwise it uses the standard diff view.
Using the git subcommand 'difftool' helps selecting a tool for displaying
side-by-side views of two (or even more) versions of a file.
Some useful ways to use this:
git difftool --tool-help
git difftool 3 4 (in combination with tags 3 and 4, see 'tagging')
git difftool --tool=vimdiff
Using an external differ is also possible with these steps:
- Use or install a program capable of showing differences in a useful way
- Use a script to start that program with the correct parameters
- Make GIT_EXTERNAL_DIFF and let it point to the script
.bashrc
Put GIT_EXTERNAL_DIFF in your ~/.bashrc
#
# Git stuff
#
export GIT_EXTERNAL_DIFF=$HOME/scripts/gitdiffwrapper
$HOME/scripts/gitdiffwrapper
The script shown here calls a diff program (opendiff, or vim -d) and sends parameters $2 and $5, which represent the names of the repository file and working file.
#! /bin/bash
/usr/bin/gvim --nofork -R -d $2 $5
or for OSX:
/usr/bin/opendiff $2 $5
chmod 755 $HOME/scripts/gitdiffwrapper)
.gitignore and .gitkeep
Files or folders that are necessary for your project but unwanted in the git archive can be hidden from git by creating a file .gitignore in the root folder of your project. In this file you can specify files and even wildcards.
Empty folders will not be added to the git archive. In case your project needs a folder for e.g. output data, you want to be able to put an empty folder in git. To do this, create a file .gitkeep in the empty folder before committing. Be aware that this is just a convention, not an official feature of git.
Project export using Git archive
Suppose you have a project which is under Git control and you want to send only the project files in your working folder to someone else, without the .git folder. Of course you could make a full copy of the entire folder, remove the .git folder and then send the remaining stuff, but there is a better way: **git archive**. An easy way to use it is as follows:
git archive master -o myproject.tar
patch
git add --patch
lets you select the areas that have changed
Tracking the history
Various ways to diff:
$ git diff # difference between the index file and your
# working directory; changes that would not
# be included if you ran "commit" now.
$ git diff --cached # difference between HEAD and the index; what
# would be committed if you ran "commit" now.
$ git diff HEAD # difference between HEAD and working tree; what
# would be committed if you ran "commit -a" now.
$ git diff HEAD --name-only # difference between HEAD and working tree,
just a list of the files
$ git diff <commit> # difference between a specific commit and working tree
$ git status # a brief per-file summary of the above.
The most recent commit in the currently checked-out branch can always be
referred to as HEAD, and the "parent" of any commit can always be referred
to by appending a caret, "^", to the end of the name of the commit.
HEAD~n can refer to the nth previous commit
Examples:
git diff HEAD^:jack_flanger.cpp HEAD^^:jack_flanger.cpp
git diff HEAD~3:jack_flanger.cpp HEAD~4:jack_flanger.cpp
git checkout master~2 jack_flanger.cpp
#
# since/until
#
Git log --since="1 week ago"
2077 Git log --until="1 week ago"
git ls-files -- shows a list of (managed ?) files
git ls-files -- stage -- shows a list of staged files
git add path/to/new/file
git whatchanged -- geeft history
If you also want to see complete diffs at each step, use
git whatchanged -p
Tagging
With tags you can mark commits with your own labels. Suppose you want to
create your own version scheme like v1.2, v1.3, v2.0 etc. then you can
attach these as tags to specific commits.
Another application is to create a stack of tutorial examples containing
incremental changes. The student can check out the examples by their
labels, like 1, 2, 3, etc.
Tagging is described here: Git-Basics-Tagging.
An example:
git tag -a "1"
commit ...
git tag -a "2"
commit ...
git tag -a "3"
then you can do
git checkout 1
git checkout 2
git checkout 3
Note that -a when creating a tag makes the tag visible in the git logging.
If you want to tag a commit that is further down in history, just point to it by its hash or the first 7 or so digits of its hash, like this:
git tag -a "mytag" ff67480
Retrieving older files from the repository
Using git log, find the commit-id of the commit you want to retrieve. The commit-id is indicated by the SHA hash or the tag you have to it. Then check out the commit as follows:
git checkout <commit-id> .
N.B.: don't forget the final '.' If you don't add it, this will take you into a "detached head state" where you can make changes and make commits, but nothing will be saved and commits you make will be lost.
How to deal with a detached head
N.B: this applies to a git HEAD. In all other contexts, call for help.A detached head can have several causes. One is given above, when you forget to type the '.' at the end of a git checkout command.
Another cause is using a tag/SHA-hash to check out a previous commit, which makes HEAD point to an earlier node in the repository history.
Solutions:
git checkout masterReturn to the master branch with HEAD pointing to its most recent commit.
git checkout -b newbranchSwitch to another branch.
git branch tmp
git checkout master
git merge tmp
Using and/or creating a remote repository
Before you can push your code to a remote repository you first need to tell Git what your name and e-mail address are. These are meant to identify you when you submit code to a group project. The following lines do that:
git config --global user.name "John Doe"
git config --global user.email "john.doe@joesplace.com"
To see your global configuration:
git config --global --list
Common case: start with a project and a local GIT development repository. In this case you don't create an empty remote repository first but start with the one you already have.
First, clone that repository into a __bare__ repository which will serve as
a common remote repository for all developers.
git clone --bare <original_directory>
<ProjectName>.git
Second, add a remote to your original development repository, pointing to
the freshly created bare repository.
git remote add origin <path_to_repository/ProjectName>
Now push your repository contents to the remote repository and from now on let all new developers clone the remote repository.
git clone <path_to_project/ProjectName>.git
useful commands:
git fetch
git stash
git stash pop
git merge
git pull
git push
git ls-remote
How to start a project on Github

On Github (or Gitlab) you start a project and make a clone on your own computer. More often you will start a project on your local computer, put it in a local GIT repository and after a while you may decide to put it on github or Gitlab.
Create an SSH-KEY and put it on Github
To be able to push data to Github you will need an ssh-key. By giving Github your **public** ssh-key, the data you transfer back and forth will be encrypted. So how do you make a key and give it to Github?- Call ssh-keygen on the command line
- ssh-keygen will ask you where to put your new ssh-key. In general the default is ~/.ssh/id_rsa, which is normally just fine, so you can press ENTER.
- The next question you will get is to enter a pass-phrase. This is like a password, but it can be much longer and you can even leave it empty. I suggest that you give it a little sentence that you can remember
- Now you have created your key it will be stored in **two** files: ~/.ssh/id_rsa and ~/.ssh/id_rsa.pub
- View the file ~/.ssh/id_rsa.pub e.g. like 'cat ~/.ssh/id_rsa.pub' and copy the entire contents to your copy-paste buffer
- Go to your profile on Github and look for an entry where you can enter SSH keys. Paste your key in the text area, give it a name and you're ready to use your Github repositories.
Bring your project to Github
One way to do this is to create a new project on Github/gitlab and give your local repository a new remote that points to the Gitlab project. Take these steps:New repository on Github
On Github, create a new repository without any contents, so no README.md, no .gitignore or other files. You can add these later.The site shows the SSH-address for the repository, which will be something like git@github.com:<your-name>/<your-repo>.git
Copy or remember that link.
Make sure you add the ssh link, not https. Otherwise github will keep asking for your username/password every time you do a push or pull.
Go to your local repository
We assume you have already created your local repository and commited files to it. Go to the root of your working copy and (if needed) check out the main branch.Add the new remote
git remote add origin <the-link-to-your-new-repo>Verify the new remote
git remote -vSynchronize both repositories
In your local folder:git push -u origin mainWorking together on a project
Suppose you have been working on some files in your working folder. Before synchronising with other developers through the shared repository, make sure you commit all changes that you want to share. Only then can Git do a merge.Fetch all changes from the remote, inspect the changes and then merge, either file-by-file or all at once, or fetch another branch and switch to that branch.
git fetch origin mastergit diff origin/mastergit stash before merging, to temporarily store
all your local changes. Then:
git merge [file...]git merge origin/mastergit stash popIf you did a 'git stash' before merging, you may want to restore your local changes:
git stash listgit stash applyNow push your local project to Github:
git push origin masterRemote (shared) repository from scratch
git init --bareGIT over SSH or proprietary GIT protocol
git clone ssh://yourhost/~you/repositorygit push ssh://yourserver.com/~you/proj.git master:masteror
git push ssh://yourserver.com/~you/proj.git master
Bare repository: a repository that only includes the files/folders inside
the .git directory and as no working directory.
The best practice is when you want to push changes, don’t push to a
non-bare repository. If you’re going to push changes, make a bare repository
clone with Git clone --bare
git remote add
@:
push local tree to server:
git push
git rm file -- remove
git rm -cached file -- untrack
git mv file path/file -- rename
Git does not record renames but mv deletes and stores under a different name
git log -p HEAD~2.stable
git show HEAD~2
git show HEAD.file
Working with branches
| git branch [-a] | Show available branches. Currently active branch is marked with * optional -a also shows remote branches |
| git branch <name> | Create a branch |
| git checkout <name> | Check out (or.. switch to) an existing branch |
| git checkout -b <name> | Create and immediately switch to the new branch |
| git fetch git checkout -t <name> |
Create a working copy of a remote branch |
| git merge <branch> | Merge given branch into the currently checked-out branch |
For pulling all branches from a remote repo, use 'git fetch origin' first.
Be careful when pushing branches to a remote repository!
git push origin myBranch
This will push the code from the branch you are locally working in to the
branch myBranch on the remote repository, possibly causing un unwanted
merging of two branches. So pay attention to where you come from and where
you go to.
Use cases of branches
Go back in history to a point where you want to make a change. First checkout that specific commit by its HASH and make a branch (e.g. "oldstuff") where you can freely make changes. When you want to go back to the latest version, i.e the most recent commit use 'git checkout <branchname>'
git log -- to find the commit you want to go back to
git checkout ..a840083h17u803..
git checkout -b oldstuff -- create a branch for making changes to old stuff
Using hooks on a remote repository
The idea is to create a mechanism for working with several team members on a remote repository and still be able to automatically perform some post-commit actions like installing the newly committed changes on a remote web site or render a document.Prerequisites
- your local repository with working tree
- a BARE (!) remote repository
- the directory tree on the remote server which will contain the checked-out files and is of course writeable for the remote Git process. As an example, let's use /home/me/public_html/mywebsite
- ssh access to the server
git remote add
#!/bin/sh
GIT_WORK_TREE=/home/me/public_html/mywebsite Git checkout -f
chmod 755 post-receive
Submodules
See this...Primary set of git commands
git-clone
Clone a repository into a new directory.
git-init
Create an empty git repository or reinitialize an existing one.
git-log
Show commit logs.
git-add
Add file contents to the index.
to undo: "git reset HEAD <file>" will remove a file from
the index but leave the working copy intact
git-commit
Record changes to the repository.
git-checkout
Checkout a branch or paths to the working tree.
git-diff
Show changes between commits, commit and working tree, etc.
git-status
Show the working tree status.
git-diff-files
Compares files in the working tree and the index.
git-diff-index
Compares content and mode of blobs between the index and repository.
git-diff-tree
Compares the content and mode of blobs found via two tree objects.
git-ls-files
Show information about files in the index and the working tree.
git-ls-tree
List the contents of a tree object.
Secondary set of git commands
git-branch
List, create, or delete branches.
git-merge
Join two or more development histories together.
git-mv
Move or rename a file, a directory, or a symlink.
git-pull
Fetch from and merge with another repository or a local branch.
git-push
Update remote refs along with associated objects.
git-fetch
Download objects and refs from another repository.
git-reset
Reset current HEAD to the specified state.